 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly-Informed Confidence Calibration for Vision-Based Safety Prediction
May 20, 2026Reliable confidence estimates are important for safely deploying vision-based controllers in autonomous racing, where safety predictions must be derived from camera images, yet modern predictors become dangerously overconfident under test-time distribution shifts. We identify a critical perception-dynamics gap in existing anomaly signals: widely used scores, such as autoencoder reconstruction error, capture visual corruptions but miss dynamics anomalies (e.g., actuation bias, latency), where images remain plausible while the trajectory degrades. To address this, we propose an Anomaly-Informed Online Calibration approach that, without retraining any model component, fuses two complementary anomaly scores extracted from a world model: a perceptual score from reconstruction error and a dynamics score from epistemic uncertainty and control-stream statistics. Based on these fused scores, a lightweight temperature-scaling calibrator leverages test-time augmentation to selectively reduce overconfidence under shift while preserving nominal-condition performance. Experiments on a physical DonkeyCar under four real-world anomaly protocols unseen during training (darkness, blur, actuation bias, processing latency) reduce average expected calibration error from 0.184 to 0.116, a 37% improvement over the best baseline, without modifying the base safety predictor.
TEACar: An Open-Source Autonomous Driving Platform
Apr 27, 2026Intelligent Transportation Systems (ITS) increasingly rely on vision-based perception and learning-based control, necessitating experimental platforms that support realistic hardware-in-the-loop validation. Small-scale platforms for autonomous racing offer a practical path to hardware validation, but often suffer from limited modularity, high integration complexity, or restricted extensibility. This paper presents TEACAR, a 1/14- to 1/16-scale autonomous driving platform designed with modular mechanical architecture, hardware abstraction, and ROS 2-based software. The system adopts a four-layer deck structure that physically decouples sensing, computation, actuation, and power subsystems, improving structural rigidity while simplifying reconfiguration. We constructed and comprehensively evaluated the prototype of TEACAR. Its mechanical stability, structural characteristics, and software performance were quantified based on three CNN-based steering controllers. Inference latency, power consumption, and system operating time were measured to evaluate computational capability and robustness. Our experiments demonstrated that TEACAR offers a scalable, modular, and cost-effective testbed for ITS research, education, and development. Our project repository is available on GitHub.
MLE-UVAD: Minimal Latent Entropy Autoencoder for Fully Unsupervised Video Anomaly Detection
Mar 25, 2026In this paper, we address the challenging problem of single-scene, fully unsupervised video anomaly detection (VAD), where raw videos containing both normal and abnormal events are used directly for training and testing without any labels. This differs sharply from prior work that either requires extensive labeling (fully or weakly supervised) or depends on normal-only videos (one-class classification), which are vulnerable to distribution shifts and contamination. We propose an entropy-guided autoencoder that detects anomalies through reconstruction error by reconstructing normal frames well while making anomalies reconstruct poorly. The key idea is to combine the standard reconstruction loss with a novel Minimal Latent Entropy (MLE) loss in the autoencoder. Reconstruction loss alone maps normal and abnormal inputs to distinct latent clusters due to their inherent differences, but also risks reconstructing anomalies too well to detect. Therefore, MLE loss addresses this by minimizing the entropy of latent embeddings, encouraging them to concentrate around high-density regions. Since normal frames dominate the raw video, sparse anomalous embeddings are pulled into the normal cluster, so the decoder emphasizes normal patterns and produces poor reconstructions for anomalies. This dual-loss design produces a clear reconstruction gap that enables effective anomaly detection. Extensive experiments on two widely used benchmarks and a challenging self-collected driving dataset demonstrate that our method achieves robust and superior performance over baselines.
Confidence over Time: Confidence Calibration with Temporal Logic for Large Language Model Reasoning
Jan 19, 2026Large Language Models (LLMs) increasingly rely on long-form, multi-step reasoning to solve complex tasks such as mathematical problem solving and scientific question answering. Despite strong performance, existing confidence estimation methods typically reduce an entire reasoning process to a single scalar score, ignoring how confidence evolves throughout the generation. As a result, these methods are often sensitive to superficial factors such as response length or verbosity, and struggle to distinguish correct reasoning from confidently stated errors. We propose to characterize the stepwise confidence signal using Signal Temporal Logic (STL). Using a discriminative STL mining procedure, we discover temporal formulas that distinguish confidence signals of correct and incorrect responses. Our analysis found that the STL patterns generalize across tasks, and numeric parameters exhibit sensitivity to individual questions. Based on these insights, we develop a confidence estimation approach that informs STL blocks with parameter hypernetworks. Experiments on multiple reasoning tasks show our confidence scores are more calibrated than the baselines.
Online Slip Detection and Friction Coefficient Estimation for Autonomous Racing
Sep 18, 2025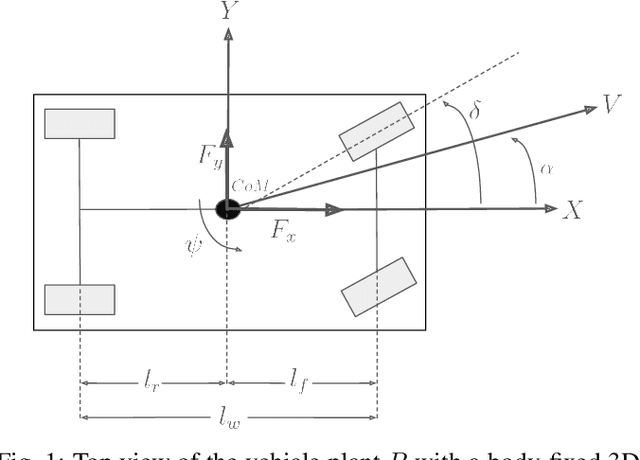
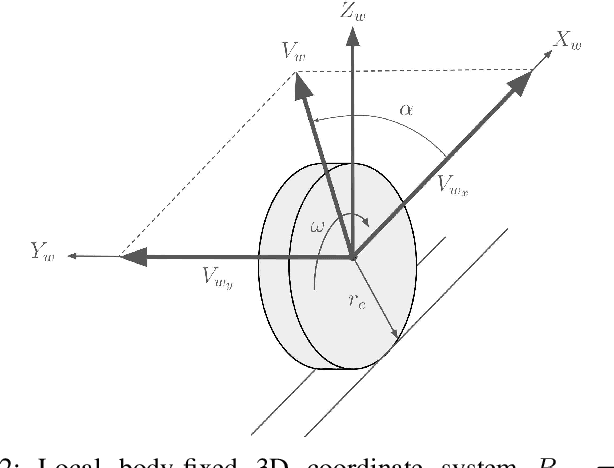
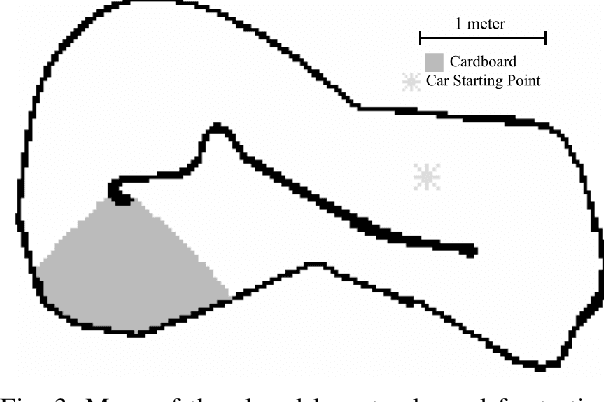
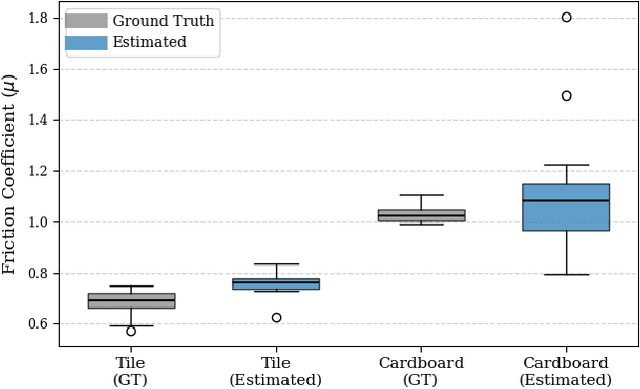
Accurate knowledge of the tire-road friction coefficient (TRFC) is essential for vehicle safety, stability, and performance, especially in autonomous racing, where vehicles often operate at the friction limit. However, TRFC cannot be directly measured with standard sensors, and existing estimation methods either depend on vehicle or tire models with uncertain parameters or require large training datasets. In this paper, we present a lightweight approach for online slip detection and TRFC estimation. Our approach relies solely on IMU and LiDAR measurements and the control actions, without special dynamical or tire models, parameter identification, or training data. Slip events are detected in real time by comparing commanded and measured motions, and the TRFC is then estimated directly from observed accelerations under no-slip conditions. Experiments with a 1:10-scale autonomous racing car across different friction levels demonstrate that the proposed approach achieves accurate and consistent slip detections and friction coefficients, with results closely matching ground-truth measurements. These findings highlight the potential of our simple, deployable, and computationally efficient approach for real-time slip monitoring and friction coefficient estimation in autonomous driving.
Towards Unified Probabilistic Verification and Validation of Vision-Based Autonomy
Aug 19, 2025



Precise and comprehensive situational awareness is a critical capability of modern autonomous systems. Deep neural networks that perceive task-critical details from rich sensory signals have become ubiquitous; however, their black-box behavior and sensitivity to environmental uncertainty and distribution shifts make them challenging to verify formally. Abstraction-based verification techniques for vision-based autonomy produce safety guarantees contingent on rigid assumptions, such as bounded errors or known unique distributions. Such overly restrictive and inflexible assumptions limit the validity of the guarantees, especially in diverse and uncertain test-time environments. We propose a methodology that unifies the verification models of perception with their offline validation. Our methodology leverages interval MDPs and provides a flexible end-to-end guarantee that adapts directly to the out-of-distribution test-time conditions. We evaluate our methodology on a synthetic perception Markov chain with well-defined state estimation distributions and a mountain car benchmark. Our findings reveal that we can guarantee tight yet rigorous bounds on overall system safety.
Temporalizing Confidence: Evaluation of Chain-of-Thought Reasoning with Signal Temporal Logic
Jun 09, 2025Large Language Models (LLMs) have shown impressive performance in mathematical reasoning tasks when guided by Chain-of-Thought (CoT) prompting. However, they tend to produce highly confident yet incorrect outputs, which poses significant risks in domains like education, where users may lack the expertise to assess reasoning steps. To address this, we propose a structured framework that models stepwise confidence as a temporal signal and evaluates it using Signal Temporal Logic (STL). In particular, we define formal STL-based constraints to capture desirable temporal properties and compute robustness scores that serve as structured, interpretable confidence estimates. Our approach also introduces a set of uncertainty reshaping strategies to enforce smoothness, monotonicity, and causal consistency across the reasoning trajectory. Experiments show that our approach consistently improves calibration metrics and provides more reliable uncertainty estimates than conventional confidence aggregation and post-hoc calibration.
Generalizable Image Repair for Robust Visual Autonomous Racing
Mar 07, 2025



Vision-based autonomous racing relies on accurate perception for robust control. However, image distribution changes caused by sensor noise, adverse weather, and dynamic lighting can degrade perception, leading to suboptimal control decisions. Existing approaches, including domain adaptation and adversarial training, improve robustness but struggle to generalize to unseen corruptions while introducing computational overhead. To address this challenge, we propose a real-time image repair module that restores corrupted images before they are used by the controller. Our method leverages generative adversarial models, specifically CycleGAN and pix2pix, for image repair. CycleGAN enables unpaired image-to-image translation to adapt to novel corruptions, while pix2pix exploits paired image data when available to improve the quality. To ensure alignment with control performance, we introduce a control-focused loss function that prioritizes perceptual consistency in repaired images. We evaluated our method in a simulated autonomous racing environment with various visual corruptions. The results show that our approach significantly improves performance compared to baselines, mitigating distribution shift and enhancing controller reliability.
Four Principles for Physically Interpretable World Models
Mar 04, 2025



As autonomous systems are increasingly deployed in open and uncertain settings, there is a growing need for trustworthy world models that can reliably predict future high-dimensional observations. The learned latent representations in world models lack direct mapping to meaningful physical quantities and dynamics, limiting their utility and interpretability in downstream planning, control, and safety verification. In this paper, we argue for a fundamental shift from physically informed to physically interpretable world models - and crystallize four principles that leverage symbolic knowledge to achieve these ends: (1) structuring latent spaces according to the physical intent of variables, (2) learning aligned invariant and equivariant representations of the physical world, (3) adapting training to the varied granularity of supervision signals, and (4) partitioning generative outputs to support scalability and verifiability. We experimentally demonstrate the value of each principle on two benchmarks. This paper opens several intriguing research directions to achieve and capitalize on full physical interpretability in world models.
NeuroStrata: Harnessing Neurosymbolic Paradigms for Improved Design, Testability, and Verifiability of Autonomous CPS
Feb 17, 2025


Autonomous cyber-physical systems (CPSs) leverage AI for perception, planning, and control but face trust and safety certification challenges due to inherent uncertainties. The neurosymbolic paradigm replaces stochastic layers with interpretable symbolic AI, enabling determinism. While promising, challenges like multisensor fusion, adaptability, and verification remain. This paper introduces NeuroStrata, a neurosymbolic framework to enhance the testing and verification of autonomous CPS. We outline its key components, present early results, and detail future plans.